
Trust in Heroku Enables DrivenData to Focus on Scaling Social Impact
Data science social enterprise relies on Heroku’s expertise to provide a secure platform for running their apps.
Sometimes the best way to solve a problem is to call in the experts. This perspective lies at the core of DrivenData’s social impact mission. DrivenData is dedicated to addressing some of the world’s toughest social challenges by crowdsourcing expertise from the data science community and working directly with social impact organizations. When it comes to setting up infrastructure for their applications, DrivenData leaves this work to the domain experts. The lean engineering team relies on Heroku to provide a fully managed app platform that allows them to focus on what they do best—building innovative applications that bring data science to the social sector.
The intersection of data and social impact
DrivenData partners with a variety of social impact organizations to help them find innovative ways to leverage the power of data in their work. Together, they explore the partner’s data sets, identify opportunities, frame problem statements, and develop hypotheses. The team can also bring in outside experts to tackle the challenge—they host competitions and invite the global data science community to submit their best predictive models or algorithms. Winners receive prizes and recognition, and some get to see their work in action. DrivenData helps to package some of the algorithms into open source tools for data scientists, software developers, researchers, and citizen scientists to drive social impact in their own projects. Behind it all lie sophisticated web apps running on Heroku that provide an engaging experience for competitors, social impact organizations, and others interested in this unique space.
From raw data to open source tool
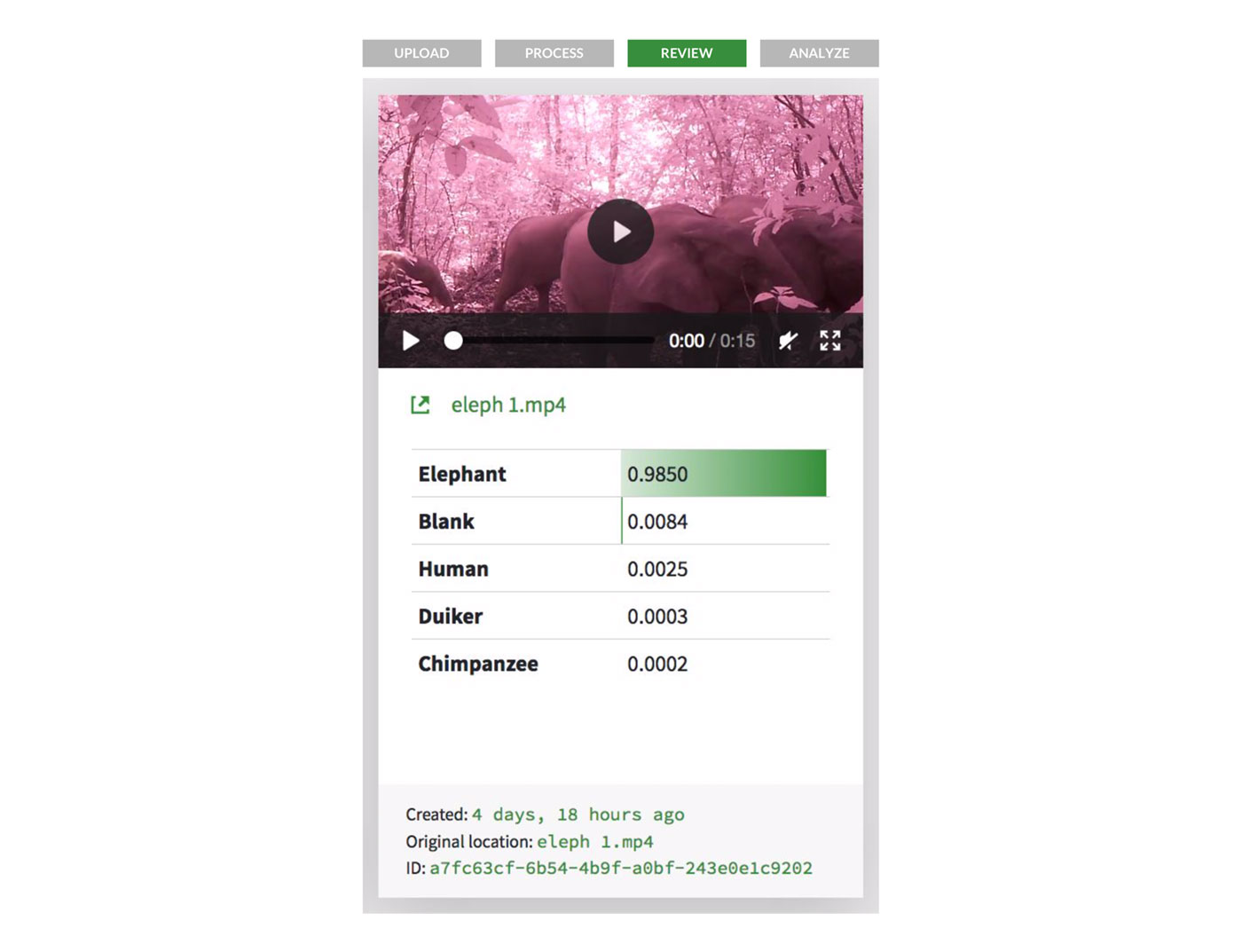
One of DrivenData’s recent projects was Zamba Cloud, a wildlife identification app running on Heroku. The challenge: researchers, conservationists, and park managers monitor wildlife using camera traps that capture photos and videos whenever animals pass by. However, this equipment generates an enormous amount of footage that must be reviewed by a human to identify specific animals and species. Often, reviewers would waste huge amounts of time on false positives, such as the movement of tree branches, as they searched for “needle in a haystack” images that could advance their work.
DrivenData challenged the data science community to help address this pain point. Data scientists from over 90+ countries participated in the Pri-matrix Factorization competition, drawing on more than 300,000 video clips to train machine learning models that could help automate wildlife identification. The winning computer vision algorithm became Zamba, an open source Python package and web app that identifies 23 animals in video data. Zamba Cloud closes the loop between data and impact by giving the conservation community a ready-to-use tool to boost their efforts. By deploying it all to Heroku, DrivenData could quickly make their tool available to those researchers who need it most.
Speed and peace of mind with Heroku
When building their initial web app, DrivenData evaluated a number of infrastructure solutions, including managing their own servers or cloud virtual machines. However, the founders did not want to take valuable time away from developing their app to focus on mundane DevOps tasks such as server configuration and management. They quickly decided that a managed solution was a better fit for their small team, and Heroku was their first choice.
Security was another deciding factor for DrivenData. As a data-focused organization, data security and user trust are a top priority, but no one on the team was a specialist in hardening systems from intrusion, or wanted to spend time managing critical updates. Choosing Heroku’s managed platform meant that security was baked into the equation. DrivenData could focus on security at the application layer and rely on Heroku’s security experts to ensure that the platform and its data services remained in full compliance with industry standards and best practices.
We take security very seriously. One of the benefits that Heroku brings to our organization is a sense of trust knowing that we’re keeping our users’ data safe. Greg Lipstein, Co-Founder & Head of Business Development, DrivenData
Staying productive with data services
When it comes to storing their data, DrivenData uses Heroku Postgres for their application data of record, such as user data and competition scores. Like the initial decision to run their web app on Heroku, choosing a managed data service made sense for the small team. The founders wanted to focus on building out their data-driven app, not on getting into the weeds of database administration. Instead, they rely on Heroku’s operational expertise and deep experience with PostgreSQL to ensure that their underlying database layer is up-to-date and secure. Heroku Postgres features, such as backups and rollbacks, allow DataDriven to manage their data as they see fit.
Heroku Postgres is run by people who spend their professional careers thinking about how to do that properly — and that's worth paying for. Often, the cheapest way to do those things right is to pay experts to do it, rather than spending developer time to build it yourself. Isaac Slavitt, Co-Founder & Data Scientist, DrivenData
Much of the application’s data processing is coordinated through Heroku Data for Redis. When a data scientist submits a new set of predictions to a competition, an automated process evaluates it against the ground truth data from the social challenge that it aims to address. This can be a computationally expensive operation, especially when multiple submissions come in at the same time. Heroku Data for Redis stores these jobs in a queue temporarily, so that the app’s worker dynos can process them as soon as they become available.
DrivenData also uses Redis for caching things like competition ranking state. Without caching, every time a user loads a competition leaderboard page, the application would have to parse the entire submission history, identify and resolve tied scores, and enforce a variety of business rules that may disqualify some scores. This is a relatively slow operation, taking approximately half a second. However, storing the leaderboard data in Heroku Data for Redis avoids the expensive calculation completely until a new submission comes in, which results in a much faster page load experience for the user.
Growing the app, scaling the mission
As a result of using Heroku, DrivenData’s small team has been able to stay productive and focus squarely on fulfilling their mission. Since launching in 2014, they’ve enhanced their platform with new features that offer greater support for their partner organizations and the data science community. Heroku has also enabled DrivenData to scale their engineering and business operations. The team can set up and run competitions at a fast pace, and thus expand their own capacity to drive social impact through data science.
The biggest advantage of using Heroku has been our ability to push out a lot more features, a lot more competitions. We can focus on our core work because we're not spending engineering time worrying about infrastructure. Isaac Slavitt, Co-Founder & Data Scientist, DrivenData
Get involved in data science!
Interested in helping to solve social challenges? Check out DrivenData’s current lineup of open competitions and submit your best solution. DrivenData also maintains a number of open source projects for the data science, machine learning, and software engineering communities.
Listen to the Code[ish] podcast featuring Isaac Slavitt: Solving Social Problems with Data Science.
Inside DrivenData on Heroku
DrivenData’s web app is built in Python and stores data using Heroku Postgres, Heroku Data for Redis, and Redis To Go. The team uses Heroku Scheduler to run jobs at specific intervals.
More case studies
-

Heroku App Helps Dutch Professionals Learn Cross-Cultural Communication Skills →
-

Emarsys Evolves from a Monolithic to a Hybrid Architecture with New Full Stack Services on Heroku →
-

Heroku Shield Helps Envoy Accelerate Delivery of High Compliance Apps →
-

Fashion Brand Builds Radically Transparent E-Commerce Business on Heroku →
In the spotlight
- View all
- Code[ish] podcasts
- •
- Blog posts
- •
- Community stories


